Research
2D Spine Recognition (vs. labeling) and Modelling
We propose a novel deep learning architecture called Transformed Deep Convolution Network (TDCN) used as a method for multi-modal vertebra recognition. This new architecture can fuse image features from different modalities, unsupervised, and automatically correct the pose of the vertebra. The TDCN-based recognition system allows us to simultaneously identify the locations, labels, and poses of vertebra structures in both MR and CT.[1]
The tasks
- Cross-modality: T1 MR, T2 MR, CT
- Recognition: Identify each vertebras location, pose, label
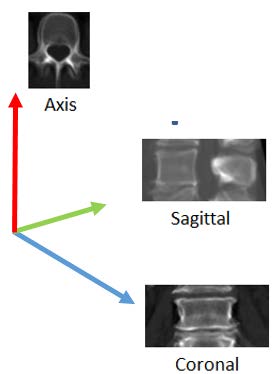
- Multiple view: Lumbar, Thoracic, Cervical
- Shape reconstruction
The task of the automatic vertebra recognition is to identify the global spine and local vertebra structural information, such as spine shape, vertebra location and pose.
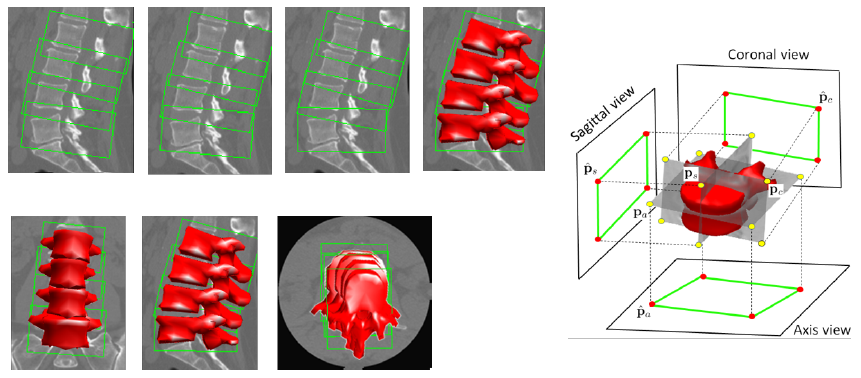
3D Spine Recognition and Modelling
We propose a novel anatomy-inspired Hierarchical Deformable Model (HDM) that implements a comprehensive cross-modality vertebra framework. The framework provides simultaneous identification of local and global spine information in arbitrary image views. The HDM stimulates the local/global structures of the spine to perform deformable matching of spine images.[2]